Standard deviations are a somewhat neglected topic when it comes to the statistical analysis of group differences. And when it comes up, it usually only for the explanation of some tail effects: A larger standard deviation leads to more outliers and beats a higher mean if you go far out onto the tail of the distribution. Brilliant example: La Griyffe du Lion’s analysis of crime rates and serial killers [1].
But standard deviation are interesting beyond these tail effects. For example environmental hardship or strong environmental influences on a trait should generally increase the standard deviation. If half of all kids in a village get a disease that costs a few IQ points this will increase standard deviation in IQ, compared to a country where this disease has been eradicated. You can often see this effect in scholastic achievement studies where the standard deviation of second generation immigrants can be notably lower than that of first generation immigrants. In second generation immigrants language ability, health and malnutrition varies a lot less than among first generation immigrants and so does every trait downstream of these.
This makes it striking that the standard deviation of IQ in African Americans and of Africans generally, is usually lower than the SD of white Americans or European populations, despite the undoubtably worse environmental conditions. African American standard deviation in IQ for example varies between 11 and 14 points compared to a white SD of 15. Given that a worse environment should increase the SD, this lower SD most likely is due to genetic reasons. In this post I want to discuss possible influences on these differences in standard deviations.
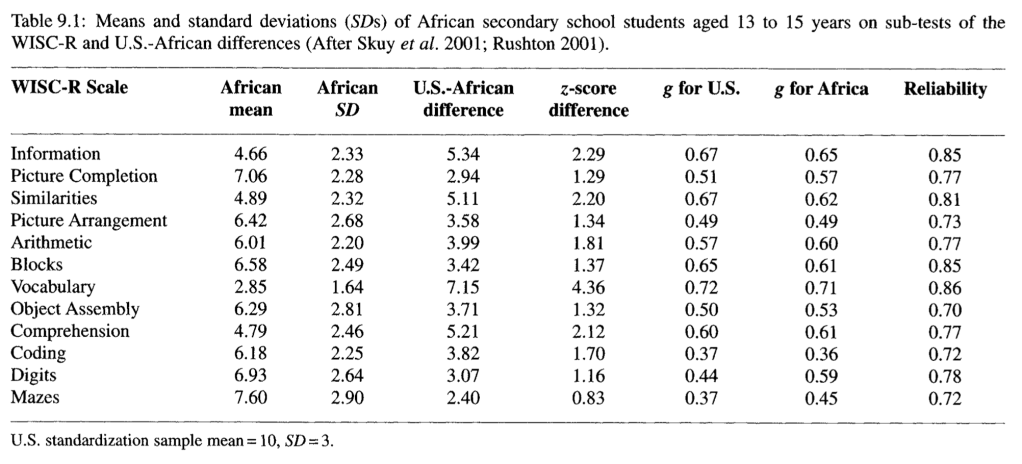
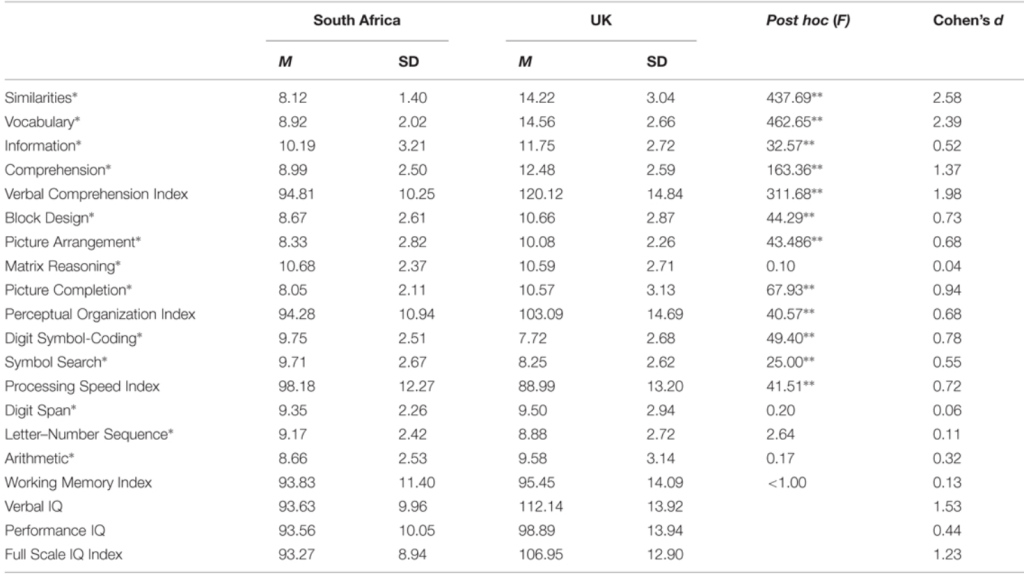
One possible influence on the standard deviation would be admixture. If a population is a relatively recent mix of two populations with a different mean, the new population would have a higher SD. Basically the variation in admixture percentage would add to the trait SD. This can be observed in Hispanics, see my blogpost [2]. Of course African Americans are an admixed population with roughly 20% white admixture, while white Americans aren’t, so purely African African Americans should have an even lower standard dev than the current population.
In non-admixed populations the standard deviation of a trait ultimately directly depends on assortative mating for that trait. It is intuitive that random mating minimizes differences because people high on a trait and people low on a trait mix genes often. Strong assortative mating sees a widening of the bell curve up to a steady state influenced by the heritability of the trait.
So one interpretation of this observation would be that environments that select for a trait are environments in which this trait is valued, which means that assortative mating is strong. In that case we would expect to see populations with a high mean to also have a high standard dev and vice versa, which is kind of what we see in IQ. But as the blogpost linked above shows, the standard deviation of violent crime is higher in Whites although the mean is lower. This seems to constitute a counter example, until we realize that the trait under selection here might be peaceful behavior.
But there are also possible explanations that don’t invoke selection pressure. For example a population that has local mating, but a global cline in the trait in question, will have globally a higher standard deviation. Such a cline is often observed in IQ where the Northern parts of many countries are higher in IQ than the Southern parts, though occasionally it is the other way round. Nigeria is probably an extreme example for such an IQ cline, see [3]. So Nigerians as a whole population might have quite a high standard deviation. However, the resulting distribution in Nigeria would not be gaussian, but multimodal, because the different ethnic groups are very much endogamous. So Whites might have higher standard deviations simply because they have historically formed larger endogamous groups or rather endogamous groups that stretch over more terrain. This explanation would predict tails that are slimmer than expected, because the distribution is not fully gaussian. This scenario is somewhat comparable to the admixture case mentioned above.
A third and maybe most convincing scenario combines aspects of the other two ideas: Maybe standard deviations depend on the historical sophistication of societies. More advanced societies lead to stronger social stratification and this in turn leads to stronger assortative mating even without changing the preferences of the people involved. Assortative mating would partly be a byproduct of assortative socializing in socially stratified societies.
[1] Why most serial killers are white men.
http://www.lagriffedulion.f2s.com/serial.htm
[2] Hereditarianism III: Discussion
https://halfassed.science.blog/2019/04/27/hereditarianism-iii-discussion/
[3] An answer to Chanda Chisala
https://halfassed.science.blog/2019/12/21/an-answer-to-chanda-chisala/