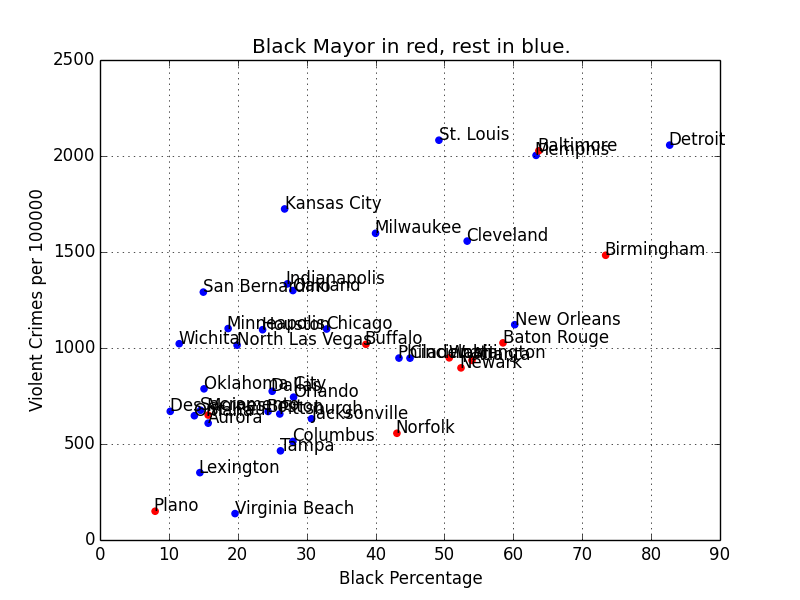
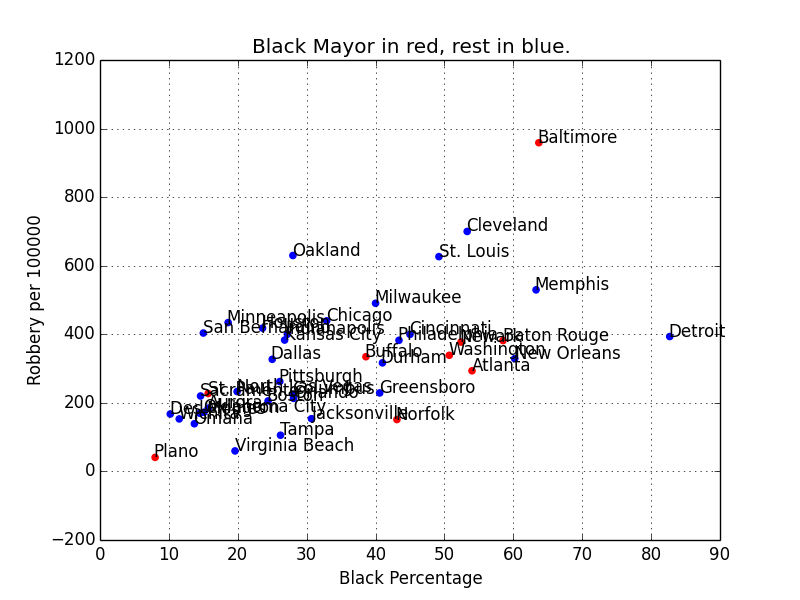
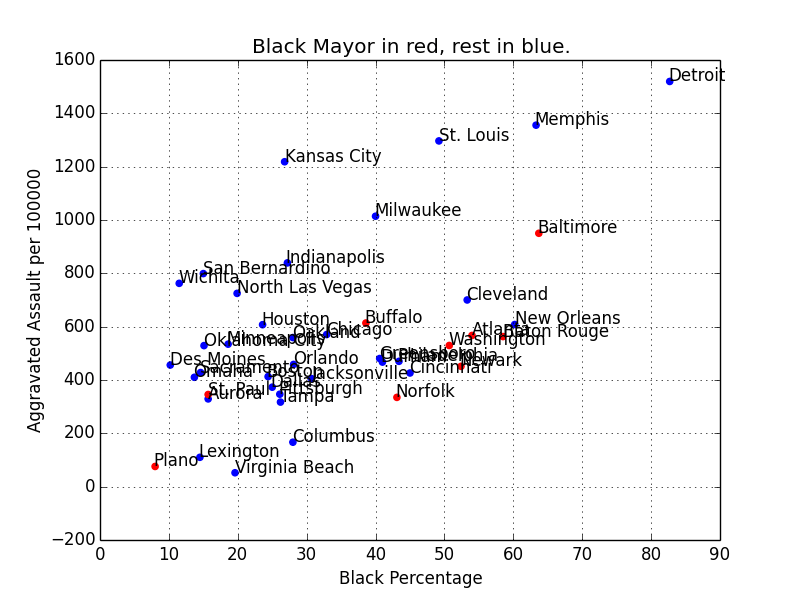
„Bias in AI“ is a popular topic these days, and usually this just means that algorithms cannot be shamed into not picking up certain pattern in the real world.
Half a year ago OpenAI published the exploits of a new Deep Learning language model called GTP-2, without publishing the larger versions of the model itself. This language model can create text that is much more coherent than was previously possible. It is trained on 40GB of articles, which makes it likely that it is severely biased in the same way as our media seems to be.
The reasoning for not publishing the model was that its capabilities make it too dangerous to put into the wrong hands. It might for example make fake news much more convincing or easy to produce. But, now, several independent replications later they started publishing larger models with the latest one having almost half as many parameters as their largest one which is as of yet still unpublished.
As this is about the biggest model that would fit into my RAM anyway, I tested GTP-2’s grasp of HBD. The prompt is my text, the samples are created by the model, which aims to coherently build on the prompt. I only excluded one or two samples that didn’t turn out coherent or grammatical. For an overview I only cite the very first sentence after my prompt:
Model prompt >>> The persistent IQ and achievement gaps between different ethnic groups are predominantly due to …
Sample1:
… ipsilateral technical dominance, or their tendency to share innovative problems and productive parts, rather than being the result of genetics. Top performers in the tribal dress component are among the most genetically gifted officials both socially and economically.
Sample 2:
… condemns from lower socio-economic backgrounds , likely reflecting environmental factors or Aryans mining wealth in the Middle East ( Hu et al., 2002 ).
Sample 3:
… erythrocytosis deficiency which may be partially compensated by factors including cosmetic surgery.
Sample 4:
… differences in transactional culture.
Sample 5:
… under- or over-selection with strong negative and positive selection processes, respectively.
Sample 6:
… differences in immigration policy patterns.
Sample 7:
… ersatz”personal”classes, not to ethnic differences in cultural relatedness, a group standpoint evolutionary economist].
Sample 8:
… vernacular, cultural and cognitive factors.
Sample 9:
… prevalent racism and the subsequent exacerbated IQ gap has a high cost.
Sample 10:
… genetically determined differences in IQ with no other neutral or intergroup effects.
Sample 11:
… bias against European-descended Black Americans
Sample 12:
… vernacular education system, not to individual differences, says Alan Kendry, professor of social policy at Victoria University in Sydney.
Sample 13:
… vernacular media and behavioural aberrations derived from biased educational models.
I am not sure what’s up with „vernacular“ but you have to be impressed by the variety of responses. These results are not nearly as biased as I assumed, though of course still heavily shifted towards environmental explanations. Out of these 13 samples at least three give a genetic reason. The „selection“ answer continues „On the other hand, other studies (for example Eurogenes 2013 and Mandarin 2007) show a genetic basis for larger and more ancillary effects on test scores at the end of high school.“ and the „vernacular, cultural and cognitive factors.“ continues with „Untreated dysfunctions of some genes not only may contribute to the variation observed between and across ethnic groups, but may position racial and ethnic groups at disadvantage relative to other ethnic groups; for example, attenuating the manifest motor skills of Jews“
Let’s finish this post with some gems that stood out among the continuations of the above responses:
There has been a larger increase in IQ among the general public by a range of thousands points on the standardised IQ test across India ( Singh and Sharma, 1980 ; Das, 2001 ). Meanwhile, socioeconomic status is negatively related to ‘intelligence levels among youth of all economic groups in the country’ ( Bhatnagar et al., 2007 ).
Yeah, thousands of points, sounds about right.
No ethnic group raises future generations in the spirit of Western society and values, and different part of the ethnic group must adjust to what it must learn from the outsider, so different ethnicities can explain themselves why they were colonized, what conditions existed for Dalits to support the government in their ancestral homes and how to impose values on all Hindu Dalits.
A glimpse into a Hindu nationalist’s mind.
If everything else is equal, the Asian (though improving) male population is asked to step up and do STEM/STEM education; the Latino female population is asked to head start an obstetrics practice.
If only these male Asians would step up and do STEM …
Equally, I would like to add credit to try to clarify what (other than Jungian/Marxist Othering) science education is meant to teach. It is morally wrong to pursue “biological determinism” and “one of many evolutionary processes” to “conform to one’s moral outlook” and then exaggerate through social engineering to “profit by social engineering” and “make money by social engineering” in the process, and that is what mentioned below. …(incoherent blathering)… Our philosophy is the same as George Orwell’s Gestapo; still gags anyone who loses to us (our ideas are so evil!)
GTP-2 simulating a Marxist, only with unusual self-knowledge.