In the last blogpost we counted a lot of names to determine how NE-Asians are represented among songwriting competition winners. In this post we take a closer look at some methods to determine ethnic composition of a dataset by surname analysis.
Without the anatomical baggage, the theory of NE-Asian relative underperformance boils down to “whatever Ashkenazim have that makes them successful (beyond the absolute IQ-value), NE-Asians probably have slightly less of it than Europeans”.
So we are naturally interested in the Ashkenazi representation among songwriting competition winners. We try to calculate it using two datasets of Ashkenazi names [1],[2]. Using the first set of names we count 17% percent Ashkenazi names among songwriting competition winners, using the second set of names we only find 6.5%. This mostly tells us that we cannot reliably assess the number of Ashkenazim with this method. There are too many names listed that are quite common among gentiles as well. And on the other hand, it is unclear how complete the lists are.
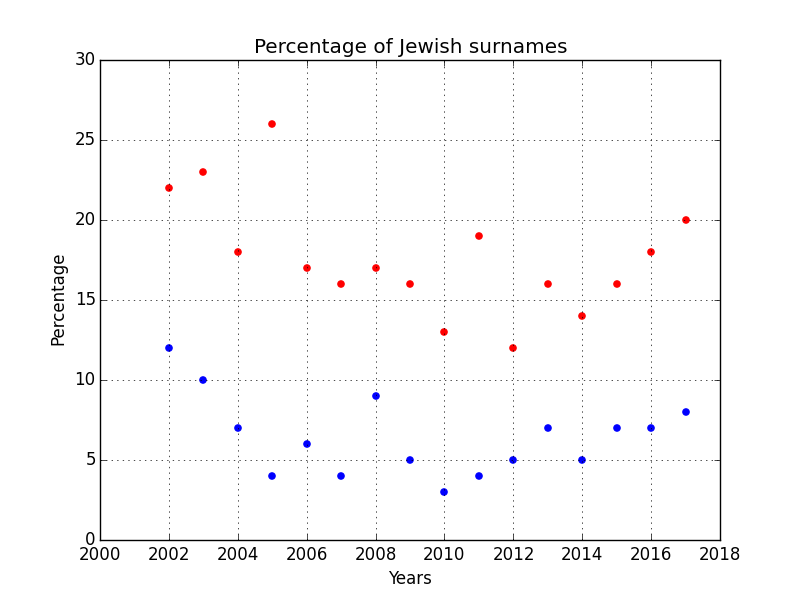
It seems counting Ashkenazim is methodologically significantly more difficult than counting NE-Asians. And of course the same holds true for African-Americans or Hispanics, who share a lot of surnames with White Americans.
Counting Ashkenazim is a time-honoured method that has been used to advance many different theories. Due to the Ashkenazi IQ advantage of 10 points, Ashkenazi overrepresentation can, for example, be used to assess the intellectual difficulty of a feat. For very high profile samples it is possible to check ethnicity by hand. For the NE-Asian songwriters this was only possible because a look at a picture is enough. Generally this is not possible for Ashkenazim which leads to a lot of potential data fudging. We would really like to do better than that.
How do we accurately and objectively assess the likely number of Ashkenazim in a sample of surnames? Let’s assume we have the probability distribution of Ashkenazi family names, i.e. the frequency with which each name appears in the Ashkenazi population. We also have the surname distribution in the general US population. Then we can create a mixed distribution of x% Ashkenazim and 100-x% non-Ashkenazim and calculate the likelihood of our sample given this mixed distribution. The likelihood is just the product of frequencies of the names in the sample. By doing this for different x we can find the mixed distribution that leads to the maximum likelihood of our sample. The x% used to create this maximum likelihood distribution is our best guess at the Ashkenazi percentage in our sample. Possibly, we have to adjust the percentage by the fraction of the population that is actually covered by our name database.
It may seem easier to just add the fractions of Ashkenazim for each name in the sample. So if we have ten names and in the general population for each of these names 10% are Ashkenazim, these ten names add up to one full Ashkenazim. Unfortunately, this undervalues overrepresented groups. In a sample with five-fold overrepresentation, these ten names should be treated as 50% Ashkkenazi. One idea would be to calculate one estimate, use this estimate to update the expected fraction of Ashkenazim for each name and then recursively get closer to the real value, but the maximum likelihood method also gives us a distribution of likely percentages.
The 2010 US census provides the surname distributions for the general US population, Whites, Blacks, Asians and Hispanics [3]. This allows us to test this method at least for these groups. For the songwriting competition winners it results in a maximum likelihood for an Asian percentage of 0.8%. This would correspond to 23 artists. Given that we only looked at NE-Asians in the last blogpost, this result is very compatible with our earlier result.

So we do have a method and we do have a motive, but unfortunately we don’t have a distribution of Ashkenazi surnames in the US. One way to get a distribution of Ashkenazi surnames would be by scraping the names of Holocaust victims from the Vad Vachem database [4]. However, that is certainly somewhat disrespectful and it is unclear whether the distribution is all that similar to the current American one. The other way is to collect names of American Jews from a variety of sources, here a hundred and there a hundred, until a significant fraction of the most common names is covered. However, I am currently too lazy to do that. But maybe I will get around to it, if something a lot more interesting than songwriting competition winners turns up.
[1] Ashkenazi names 1
http://www.avotaynu.com/books/MenkNames.htm
[2] Ashkenazi names 2
https://en.wiktionary.org/wiki/Appendix:Jewish_surnames
[3] 2010 US Census
https://www.census.gov/topics/population/genealogy/data/2010_surnames.html
[4] Holocaust victim names
https://yvng.yadvashem.org
