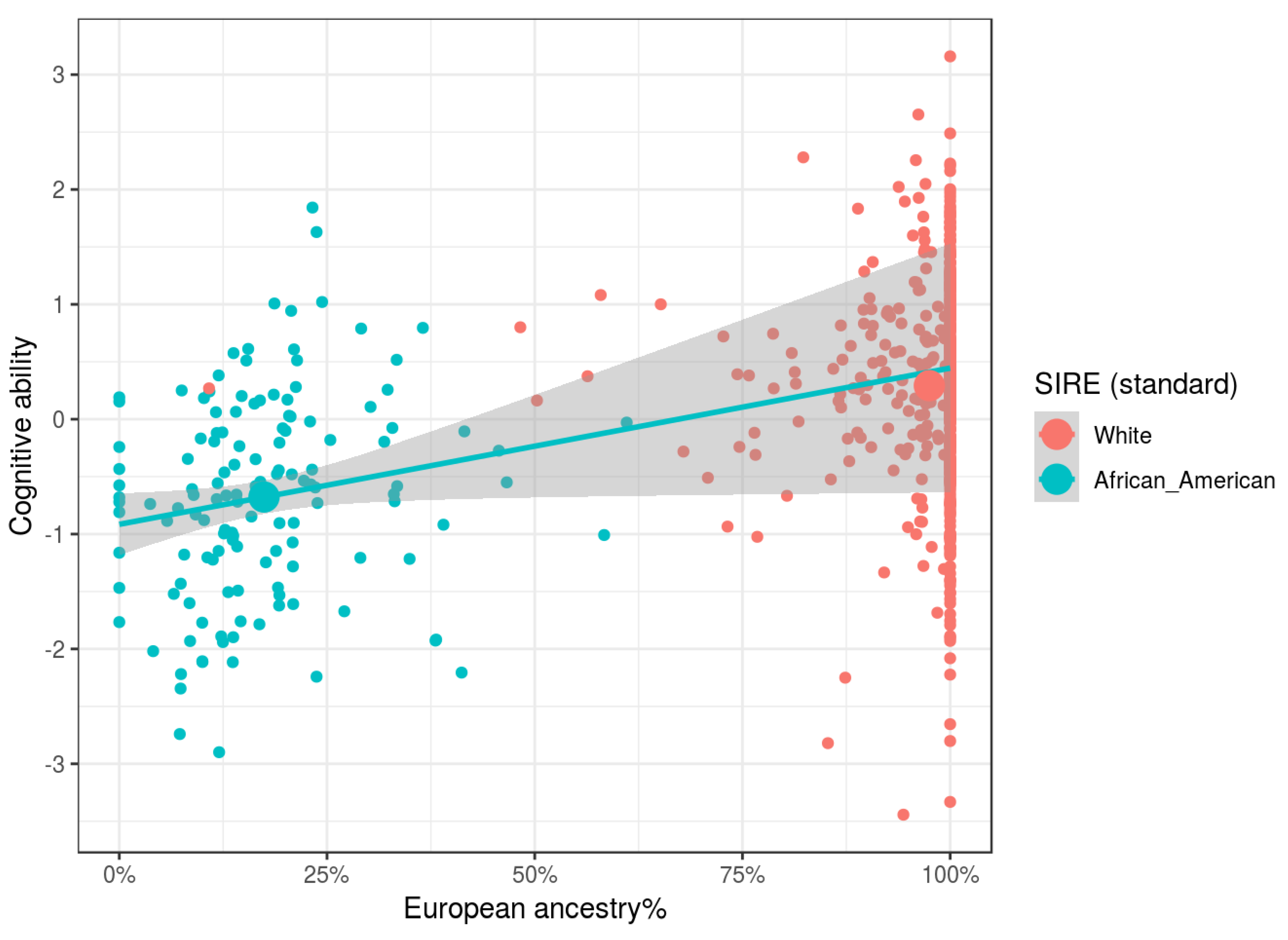
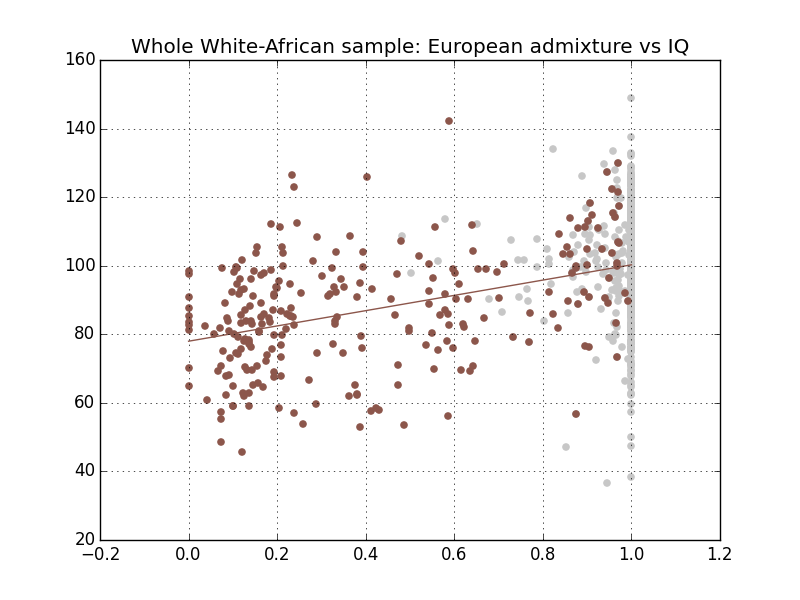
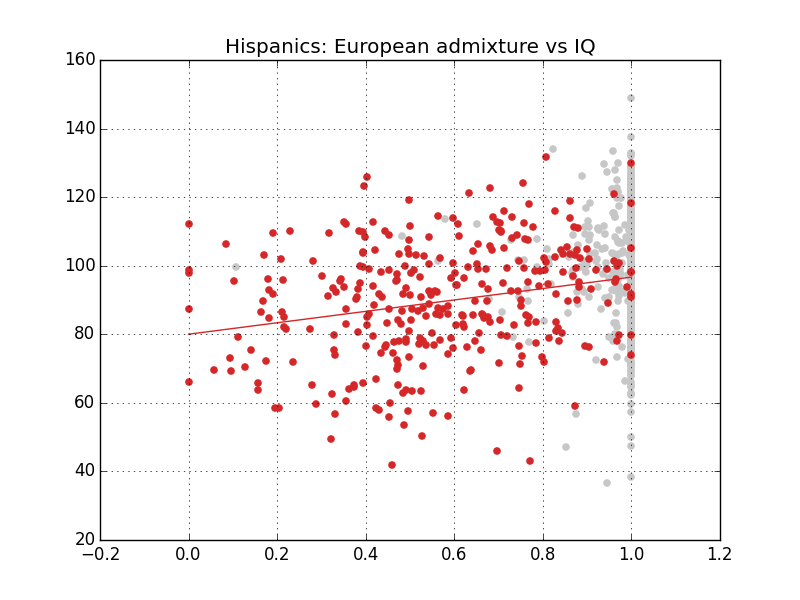
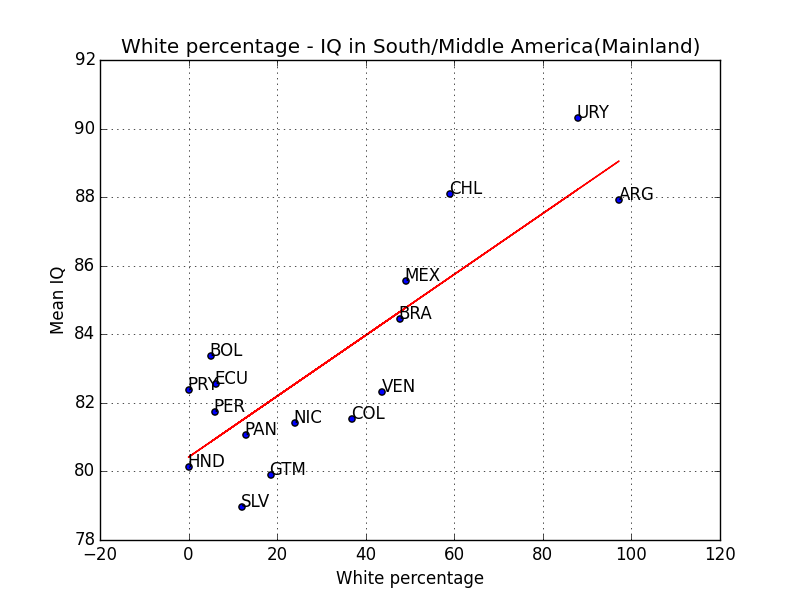
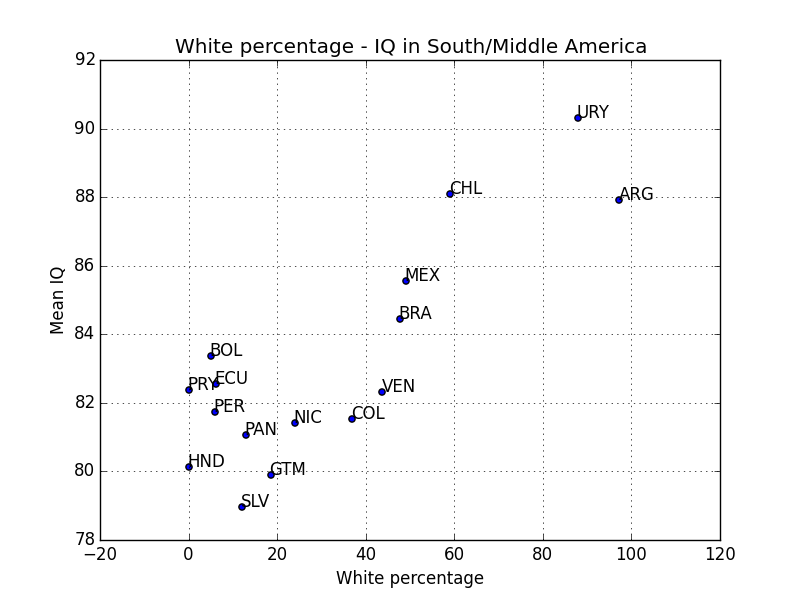
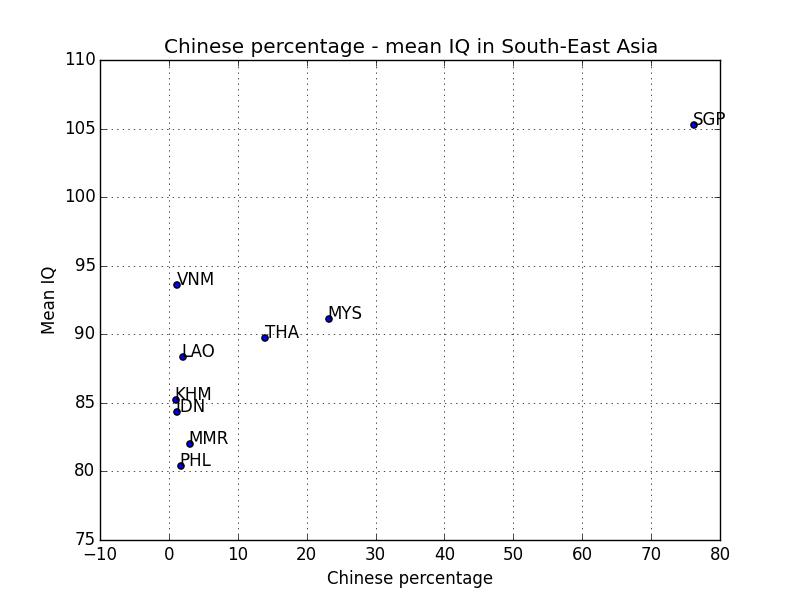
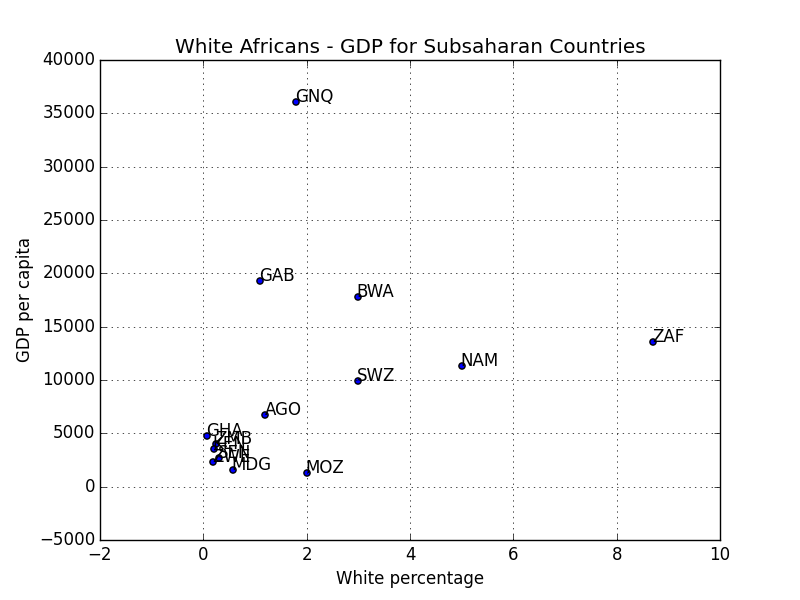
In the last post, we have seen that for African-Americans and Hispanics, IQ varies according to ancestry. In this post we will discuss what this actually means and whether there is still leeway for the environmentalist to wriggle about.
The key idea of this kind of admixture study is to show that the differences between ethnic groups can entirely be explained by genetic factors. This is done by showing that the IQ differences within each ethnic group by ancestry extrapolate to the differences between ethnic groups. So it is essential that we only look at IQ and ancestry within each ethnic group.
Without a strict restriction to one ethnic group, it would not be enough to prove that IQ correlates with admixture. We already know that there is an IQ gap and we already know that there is an “admixture gap”. So a correlation is already a given.
But what if the self-identified ethnicity is noisy? For example some of the “Hispanics” might actually identify or be identified as White. In that case the correlation between ethnicity and IQ would bleed over into the IQ-admixture. Of course this assumption borders on paranoia. But the correlations observed are quite small, which means that admixture explains very little of the IQ variance in the data set, which might seem counterintuitive from a hereditarian perspective.
So what kind of correlation should we expect? If the European-Amerindian-gap is 16 points, similar to the Hispanic standard deviation, shouldn’t we expect admixture to explain a very significant part of the variation? Well, actually not. If admixture is uniformly distributed the mean difference in admixture between two Hispanics is only 33.3%. This means the average IQ difference explained by admixture would at most be 5-6 points. But the admixture is not uniformly distributed, Hispanics with less than 40% European admixture are notably rarer. This is why the actual standard deviation of admixture is just 23.3. So we are down to less than 4 points explained by admixture. This would lead to a correlation of 0.50 … given perfect data. But both the admixture data and especially the IQ data invariably contain noise, reducing this correlation further. So it is actually not surprising that we only see correlations between 0.17 (for the very range-restricted African Americans) and 0.41 (for much more uniformly distributed African-European Hispanics).
A better way than looking at correlations to drive home the meaning of the hereditarian hypothesis is to visualize how mean IQ of percentiles change. The hereditarian hypothesis posits, that IQ varies continuously with admixture. This means that the IQ averages of admixture percentiles will more or less linearly increase.
To show this effect for each percentile would require a much larger data set. This data set is almost too small and heterogeneous to show the effect convincingly for quartiles. For example, as we have seen, the Hispanic IQ is slightly depressed compared to the same admixture in African Americans. Because the middle region of European admixture is dominated by Hispanics this results in a depressed middle if we use the whole sample.
Instead we restrict ourselves to the Hispanic sample. Because the mean White and mean Asian IQ in our data is almost identical, we can just pool European and East Asian admixture to create a well-powered Hispanic quartile admixture plot:

Here, we see that the average IQ of the admixture quartiles fall pretty nicely on the regression line.
This plot perfectly illustrates the hereditarian hypothesis: The averages vary exactly according to admixture. (Note also, that if we plot a line through the first two quartile averages only, we would overshoot the mean white IQ, presumably because the lowest quartile is slightly environmentally depressed. This might be happening in the African-American sample.)
It is tough to come up with environmental causes for IQ differences that vary according to ancestry. Colorism is one of the best tries. Colorism is the idea that racism is graded by how dark somebodies skin is, which varies according to ancestry, and that this racism somehow reduces IQ. Except when you are NE-Asian … Colorism as the reason for IQ varying with ancestry, is a theory that has a lot to prove before it can be remotely taken seriously.
However, IQ varying by ancestry also doesn’t prove that the gap is fully genetic. Or, to put it differently, even if we could predict IQ perfectly directly from the genome, it remains theoretically possible that there are gene-environment feedback mechanisms involved that allow us to reduce the magnitude of the gap by improving living/learning conditions. Of course the history of intervention studies tells us not to hold our breath.
So, what are the take-aways from this series:
- IQ varies by ancestry within ethnic groups with the same country of birth.
- This intra-ethnic variation fully explains IQ differences between ethnic groups.
- This invalidates most environmental explanations for the IQ gaps.
- And strongly suggests a genetic reason for IQ gaps between ethnic groups.
- Ancestry nonetheless explains little individual IQ variation – people should be judged as individuals.