Duf 1220 is a fascinating specimen [1]. It’s a protein domain, i.e. a conserved part of a protein, and mammals generally have several copies of its coding sequence. The number of Duf 1220 copies rises with increasing cognitive sophistication of the animal. It correlates with brain size and number of neurons in the neocortex. Humans underwent rapid copy number expansion since our split from Chimpanzees, so it might just be an essential part of what made us human.
There are several slightly different versions of Duf 1220: Three versions conserved in mammals, CON1, CON2, CON3, and three human lineage specific versions, HLS1, HLS2, HLS3. CON1 copy number variation has been correlated with symptom severity in both autism and schizophrenia. More copies increase the severity of autism symptoms [2], but ameliorate the symptoms of schizophrenia [3]. This is a data point in favor of a hunch many people seem to have, that autism and schizophrenia are to a certain degree opposites.
The more interesting finding, however, concerns CON2. There is a 2014 paper that shows a correlation between CON2 copy number and IQ, as well as between CON2 copy number and mathematical aptitude in two different populations [4]. And while the correlation is not very strong, the effect size is pretty big: A one copy increase is associated with a rise of 3.3. IQ points (CON2 copy numbers varied from 26 to 33).
There is a caveat here, that the populations had been selected for unusual brain sizes, apparently because Duf 1220 mutations have also been implicated in cases of microcephaly and macrocephaly. So it is hard to say how this would generalize to the population at large. There also hasn’t been a try yet to replicate this result, though the whole genome sequencing data that UK biobank is aggregating in 2018/19 should be ideal for that, so hopefully it is only a matter of time.
This could present a major roadblock for polygenic scores for IQ that capture a significant part of the variation. These polygenic scores are computed on the basis of SNP-sequencing, so basically a couple of hundred thousand known genetic variants are looked up for hundreds of thousands of people and then these variants are correlated with a measure of IQ. Such polygenic scores are expected to capture almost all of the genetic variation in one of the upcoming studies, as the data sets approach a million genomes and more. SNP-data, however, doesn’t give you copy numbers. So if a significant part of the genetic variation in IQ is due to copy number variation, the upcoming polygenic scores for IQ will miss out on that.
There is another major thing Duf 1220 exploration might bring about. For better or for worse, it might give an undeniable genetic underpinning to IQ differences between ethnic groups. This is something polygenic scores cannot do fully convincingly. Because they were calculated on the basis of a particular population, there is always the possibility that other populations just have other causal variants, or maybe the same causal variants but tagged by different non-causal variants. Duf 1220 copy numbers provide an absolute scale. If they are strongly correlated with IQ and some groups just have more copies, that would be it.
There is data out there to test this hypothesis. The 1000 Genomes Project has collected whole genome sequencing data from more than 2000 persons coming from a few dozen different populations [5]. I was already gearing up to find out how to extract the copy numbers directly from the genome data. It would have been pretty annoying, starting with the fact that Duf 1220 has changed names three times and is not even a full protein, so it was already difficult to find out the exact sequences I was going to look for [6].
Thankfully, I came across a paper that presented a new method to accurately extract the Duf 1220 copy numbers from crappy whole genome data … such as provided by the 1000 Genome Project [7]. So I could just extract the copy numbers for each population from this paper and calculate the correlation with national IQ. They calculate the copy numbers for only a subset of the genomes (300 out of >2000) and ethnicities (14 out of 26), so it would still be interesting to do this for the whole data set, but for me this is obviously good enough.
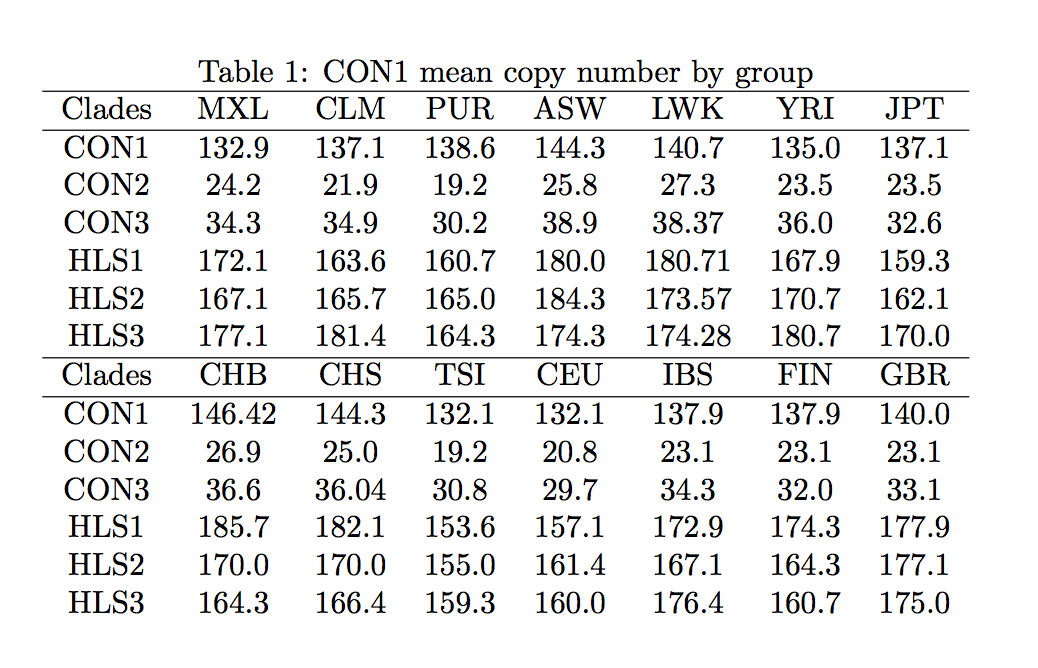
I extracted the mean copy numbers with a ruler from a figure, but it should be reasonably accurate. The population code is MXL, CLM, PUR, ASW, LWK, YRI, JPT, CHB, CHS, TSI, CEU, IBS, FIN, GBR for Mexican, Colombian, Puerto Rican, African American, Kenyan, Nigerian, Japanese, Chinese North, Chinese South, Italian, US White, Spanish, Finnish and British. I must say, the big differences between US whites (CEU) and the British (GBR) sample make me suspect that these samples are not terribly representative.
Here are the correlations and p-values of the copy numbers of these different Duf 1220 clades with mean IQs (mostly taken from [8])
CON1: (0.1804623575126954, 0.5369859560902486)
CON2: (-0.04461569460636064, 0.8796236514733563)
CON3: (-0.36827828175357813, 0.19510798215034106)
HLS1: (0.06364079402648662, 0.8288796633160219)
HLS2: (-0.2970184131107142, 0.30242890306660486)
HLS3: (-0.5856985689802922, 0.027751781117769762)
So the only correlation <0.05 is actually negative! And given that we tested five hypothesis in parallel here, not even that one can be called statistically significant.
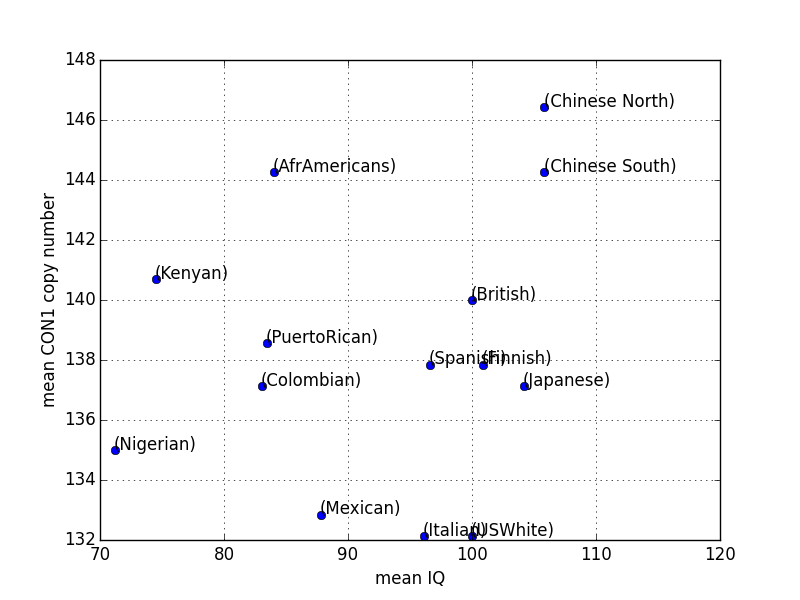
However, if we take a look for example at the figure for CON1, there is a visible correlation on the right hand side, which corresponds to Eurasians. And indeed, if we restrict the data only to the Eurasian groups, we get two strong positive correlations with p<0.05 for CON1 and CON2. Of course, this proves nothing at all, except that eyeballing data is enough to conjure low p-values out of thin air.
CON1: (0.7388255579312805, 0.03626967465109577)
CON2: (0.7989439868399302, 0.017377816927201657)
CON3: (0.5982538032770237, 0.11718547045755617)
HLS1: (0.5299319863071927, 0.17672986976320368)
HLS2: (0.38298701194336177, 0.34902961674689775)
HLS3: (-0.05335949442713573, 0.9001406945527723)
But we are allowed to take this as an encouragement to revisit this question as soon as better data is available.
[1] https://en.wikipedia.org/wiki/DUF1220
[2] DUF1220 Dosage Is Linearly Associated with Increasing Severity of the Three Primary Symptoms of Autism
https://journals.plos.org/plosgenetics/article?id=10.1371/journal.pgen.1004241
[3] DUF1220 copy number is associated with schizophrenia risk and severity: implications for understanding autism and schizophrenia as related diseases
https://www.nature.com/articles/tp2015192
[4] DUF1220 copy number is linearly associated with increased cognitive function as measured by total IQ and mathematical aptitude scores.
https://www.ncbi.nlm.nih.gov/pubmed/25287832
[5] 1000 Genomes Project
http://www.internationalgenome.org
[6] A proposal to change the name of the NBPF/DUF1220 domain to the Olduvai domain
https://f1000research.com/articles/6-2185/v1
[7] High resolution measurement of DUF1220 domain copy number from whole genome sequence data
https://bmcgenomics.biomedcentral.com/articles/10.1186/s12864-017-3976-z
[8] IQ database curated by David Becker, based on the original Lynn database
http://viewoniq.org
