In 2002 Richard Lynn and Tatu Vahanen published “IQ and the Wealth of Nations”, a book based on a database of national mean IQ scores collected from many different sources [1]. This has made a lot of people very angry and been widely regarded as a bad move.
There are a lot of studies that measure the IQ of their probands, often as only one of several indicators. A typical example would be trying to establish the adverse effects of malaria. Here, you would have a group of people afflicted with malaria and a control group representative of the population. By comparing both groups in IQ, SES, health and what-not, you can establish that malaria is a bad thing to happen to you.
Now, Lynn comes along and doesn’t give a damn about malaria. Instead he just scoops up the mean IQ of the control group, which gives him one measurement of the typical IQ of this population. However, due to the Flynn effect, you cannot easily compare IQ across time in a fair way. So if the IQ test used, was normed ten years earlier, say in the UK, you have to discount this mean IQ by the Flynn effect over ten years in the UK. This would amount to roughly -3 points and gives you a comparison of this population and the British in the year of the study in terms of IQ.
This results in a database that is easy to criticize. Many of these studies are not very carefully conducted, after all, they were never meant to create representative mean IQs of a national population. The Flynn effect is not well understood and correcting for it can seem arbitrary and a little dodgy. However, this database now exists and it is still maintained and improved by one David Becker [2] and, as we will see, it contains very interesting information.
The correlations
But how do we tell, that this offensive database is not just noise?
Well, for starters the national IQs correlate very significantly and quite strongly with
human development [3]: correlation 0.821, p< 1.165e-36
This shows that the database does not contain “just noise”. There is actual information in there, about stuff we usually care a lot about. Of course, many very different relationships can result in a correlation between two variables. Over the next posts we are going to go deep on one of these relationships: The one between national mean IQ and GDP per capita.
In the last post we presented three mysteries, the relatively small brains of the highly intelligent Ashkenazi Jews, the scientific and economic underperformance of North-East Asian countries relative to their mean IQ (around 105), and the Flynn effect of rising IQ scores during the 20th century.
To arrive at a theory capable of resolving them, we will discuss first the Ashkenazi cognitive profile and then a simplified model of the neocortex.
The Ashkenazi cognitive profile
Freud, Einstein, Marx.
Often most impressive about famous Jewish thinkers is their ability to put a lot of different and seemingly unrelated facts into a big conceptual framework. Sometimes that results in nonsense, sometimes in pure genius, and sometimes it changes the world.
It also seems to be the driver behind the crazy percentage of Nobel prizes in economics collected be Ashkenazim. A slightly uncharitable description would be that Ashkenazim seem to have a unique ability to create just-so stories. Examples for this ability are easy to come by [1],[2],[3].
The IQ profile of Ashkenazim is unusual as well. They excel at mathematical and especially verbal tasks, though they seem to lag slightly behind other Europeans when it comes to visuo-spatial IQ [4].
The biological underpinning of these extraordinary abilities are suggested by the two big genetic disease clusters typical for Ashkenazim, one increases dendritic growth, i.e. the ability of neurons to form synapses with other neurons, the other hampers DNA repair, which is conjectured to also boost the number of synapses created in the brain [5].
This implies that the fast creation of new connections is the driver behind the high Ashkenazi IQ.
A cartoon model of the human neocortex
For the purpose of this blogpost I introduce a very simplified model of the human neocortex, the seat of human intelligence.
The cortex can be viewed as consisting of pattern recognizers, which have three kinds of input connections [6]: The feedforward input that contains the actual pattern uses only 20 percent of the dendritic connections of this pattern recognizer. The remaining 80% are distributed between lateral connections, which provide temporal context and therefore facilitate sequence learning, and feedback connections, which provide overall context.
A theory of IQ
My hypothesis is that the faster creation of lateral synapse boosts the verbal IQ of Ashkenazim, while easier creation of feedback connections allows for the conceptual and analytic excellence that distinguishes Jewish thinkers.
If this hypothesis is correct, the slightly lower verbal IQ of NE-Asians suggests a slightly lower number of synapses being created. An overall lower creation of feedback synapses would also lead to a lower ability to come up with creative conceptual theories. This ability is difficult to test and therefore doesn’t show up in the “lab”. But it is more plausible than verbal IQ to be the essential ingredient for economic and scientific success.
The full correspondence I suggest is that the number of pattern recognizers determines visuo-spatial and mathematical IQ. The number of lateral synapses corresponds to verbal ability and the top down connectivity to the ability to create new high level concepts.
But wait a second, don’t the Ashkenazim have very high mathematical IQ as well? Quite right, and they achieve that by re-purposing part of the visual cortex for higher level patterns. Basically evolution just shuffled IQ points from spatial to mathematical, by reassigning pattern recognizers.
With that last little flourish everything falls nicely into place, the IQ profiles, the brain sizes, the underperformance relative to IQ.
The Flynn effect can now be explained by brain size increase via better nutrition and fewer childhood diseases [7],[8]. This fits perfectly to a puzzling aspect of the Flynn effect, namely that the gains have been enormous on pure pattern recognition tests, like the Raven’s, while IQ tests based on sequence learning, like verbal IQ or digit span have shown little or no Flynn effect.
If the half a standard deviation bigger NE-Asian brains do a standard deviation better on spatial reasoning/maths than European brains, it is not unreasonable to assume that the increase in brain size by more than a standard deviation [7],[8] during the 20th century might account for the whole Flynn effect on the Raven’s which is more than 30 points.
Of course, the brain is lot more complicated than my simple model suggests. The hippocampus, the basal ganglia, the thalamus, etc. all likely play a essential role in human intelligence. The Flynn effect might have several additional causes, especially education seems to be a candidate that shouldn’t be neglected. However, as a very rough overview, this seems to be a useful framework.
This is the first of two parts. Here, we discuss three mysteries in IQ research. In part two we will propose a theory of human intelligence that resolves them. The three mysteries are the Ashkenazi brain size-IQ outlier, the North-East Asian scientific and economic underperformance relative to their IQ, and the Flynn effect.
Brain size-IQ connection
It has long been known that brain size and IQ are correlated. Modern fMRI-studies confirm this relationship [1]. The correlation is relatively weak. However, even weak correlations can approach unity, if we average over groups and the other influences average out. Asians, Whites and Blacks sort in the same way by brain size and by IQ and the observed differences seem to very similar in terms of standard deviations [2]. Only the Ashkenazim with the highest IQ of all, fall out of that pattern, with an average brain size slightly below the white mean [3].
The Flynn effect
The Flynn effect is the phenomenon that over the 20th century IQ performances rose enormously [4]. In some types of tests this increase is more than 2 standard deviations. The Flynn effect is mysterious because we neither know what the root cause is, nor do we know what this increase means in practice. Nutrition, education, changes in worldview (“scientific goggles”) and several other causes have been proposed, it hasn’t been a slam-dunk for any of these. While the scores went up, people do not seem to be smarter than two or three generations ago.
North-East Asian underperformance
North-East Asians do pretty well. Of all groups out there, they alone have closed the gap to western levels of affluence (or in the case of China, are about to). In what way do they underperform? The mystery lies in the fact that they enjoy quite a pronounced IQ advantage compared to western nations, which doesn’t seem to translate into higher GDP or scientific output. They do well, but not as well as they should.
If we compare Japan and Germany, for instance, we find a pretty similar history: Late comers to the international stage, they went through a phase of nationalism and militarism that ultimately led to WW2 and the destruction of their countries. The countries were rebuild and quickly entered the economic elite again. This makes them ideal for a comparison that highlights the NE-Asian underperformance:
Japan enjoys an IQ advantage that is currently estimated at 6 points (105 to 99 or thereabouts). This should be enough to leave Germany in the dust when it comes to GDP. However, instead they lag behind with 38,428 vs 44,469 USD per capita.
Their population is 50% larger. Their work hours are 50% longer. Their total GDP is higher and the percentage of GDP they put into research and development is higher too [5]. Still, the Japanese lag behind the Germans in most indicators of scientific output [6].
There are several competing explanations that revolve around a lack of creativity, curiosity or testosterone [7]. Or too much conformism and hierarchy. La Griffe Du Lion proposes that it is the verbal IQ that determines GDP (and apparently scientific output) [8]. This would resolve the paradox, because while the high NE-Asian IQ depends on a very high mathematical-spatial IQ, in verbal tests they often lag slightly behind Europeans.
However, this explanation is only mathematically satisfying. Why would verbal IQ be so exclusively important? Aren’t the quantitative skills the most valuable on the labor market?
Mutational load and purifying selection are two important concepts in genetics. While mutational load is somewhat intuitive, purifying selection can be quite confusing to the layman, once you start to think about it in some detail. Here’s how I think about mutational load and purifying selection, after spending a long walk thinking through my confusion.
As you well know, every child inherits a set of chromosomes from each of her parents. But these aren’t perfect copies, instead they will contain around 60 copying errors. These errors are strewn randomly into the genome and because random changes to a complicated machinery are very unlikely to be beneficial, almost all of them will either be neutral or have a negative effect.
Now this has been happening for generation after generation and the negative mutations accumulated in a creature or a gene pool are called mutational load. If there were no mechanism to get rid of mutational load, something called mutational meltdown would occur: A species becomes so riddled with mutations that its members are no longer functional and it goes extinct. This typically happens when population size falls under a critical threshold and it might have wiped out the Flores hobbit.
Purifying selection is the mechanism that is balancing these ever accumulating negative mutations. The idea is basically that creatures with more load are less fit in an evolutionary sense, so they have fewer offspring, while creatures with less load pass their relatively pristine chromosomes on to the next generation.
Of course the devil is in the detail. Imagine you look only at the individual with least mutational load in every generation. This magnificent creature might almost always pass on its genes, but remember, every time it’ll add new mutations. So the very top seems to be slipping inexorably downwards with every generation and the whole species must be sliding into the shredder.
Now people might come up with the idea that the very top is propped up by positive mutations, which do happen. While almost all offspring is worse off than their parents, some might strike lucky and get additional positive changes. Well, that might work for bacteria, for human beings, forget about it. Positive mutations are way too rare and the number of children is way too small.
Instead the correct way of looking at purifying selection is the following: Imagine the genomes of your mom and your dad are made of parts. These parts always exist in two versions and every part is either perfect or somewhat damaged, maybe even broken. Each parent gives you a copy of a randomly selected version of each part. Now you can see how you might beat the downward ratchet of mutation: If you get lucky and just happen to get most of the perfect parts from your mom and most of the perfect parts of your dad, you can easily end up with more perfect parts than either, even after some of the parts have been damaged in the copying process.
This is what purifying selection actually operates on: The number of perfect parts. The question remains, what are these parts? One part of the answer is chromosomes, but chromosomes are way too big. You can easily generalize the argument about the degenerating top creature to each particular chromosome type in a population. Instead the key is recombination. Recombination allows chromosomes to literally exchange parts. Two chromosomes neatly aligned to each other break at the same position and then are mended with the half of the other chromosome. So with just two recombinations you can exchange every subsequence in a chromosome with the corresponding subsequence in the other version. These subsequences are the parts and they can be any size from a few bases to a whole chromosome. This mechanism gives purifying selection its power and it’s probably one of the main reason for the existence of sex.
Purifying selection and negative mutations reach a balance that is determined by the mutation rate and the selection pressure. And the important thing to note is that this balance is nowhere near the top of the local optimum of the fitness landscape. Olfactory receptor genes might be a decent illustration of this: OR genes encode receptors for certain smells. If one of these receptor genes has no functional part in your genome, you wont be able to detect the respective smell, which is quite unlikely to be a positive thing. In humans, of around 1000 OR genes found in our genome, generally only about 400 are functional. The picture that presents itself is that having an acute sense of smell got less and less important in our recent evolutionary history which translated into reduced purifying selection and the number of functional receptors slowly dropped towards a new balance between selection and mutation which likely hasn’t even been reached yet. A balance that is obviously far away from an optimum of having a full 1000 functional receptors.
Most of the slightly negative mutations don’t have this kind of localized effect. Instead they just make some metabolic pathway slightly less efficient in every single cell of your body. Which leads us to the next important point.
When the Human Genome Project was in full swing there were many enthusiastic expectations about how finding “the gene for cancer” or finding “the gene for Alzheimer’s” was going to lead to medical breakthroughs. This optimism persisted for a couple of years after the completion to then slowly scurry into a corner and die. Of course there are a lot of diseases that are caused by a single damaged allele, the so called mendelian diseases. But these diseases aren’t the big scourges of mankind, because a single allele that is extremely negative is effectively purged by purifying selection and therefore rare. (The exception being stuff like sickle-cell anemia which gives some protection against malaria.).
Instead a lot of common diseases like autism, schizophrenia, diabetes have turned out to be massively polygenic, i.e. thousands of mutations contribute very slightly to the risk of getting the disease. Sounds familiar? And this is not just the case for diseases, many interesting traits like IQ or height have turned out to be highly polygenic as well. Now it could be the case that all these alleles are not net-negatives, but instead involve some kind of trade-off and that is probably part of the picture. But research has shown that IQ is largely determined by rare slightly negative alleles, whereas in a trade-off scenario you would expect something more like 50:50 between positive and negative contributions of rare alleles. Also, most positive traits seem to be correlated, which points to a common underlying cause. These observations fit the theory that most polygenic traits are heavily influenced by mutational load.
Now, the worrying conclusion from these observations is that currently our industrialized societies are sliding towards a lower balance between mutation and purifying selection, as selection has been massively relaxed with the help of medicine and social security nets and as the most capable people are having the least kids due to a very long education. How fast we slide is a topic of debate and how far we will fall is anybodies guess. The best way seems to be to avoid finding out what the new balance would mean for our collective health and IQ. The exiting part is that mutational load gives us an uncomplicated handle on the functioning of our massively complex genomes. Generally we don’t have much of a clue how our genes give rise to different phenotypes. Every non-trivial change made to our genome is a shot in the dark with usually incalculable risks. Mutational load on the other hand is easily determined by just counting how rare an allele is in the population. Basically every deviation from a consensus genome is exceedingly likely to be negative or at least non-positive. Some people think that Crispr/CAS9 will be used to purge mutations from our genomes and they might be correct. But at the moment it is completely unclear whether it will become possible to do genome editing without off-target effects on thousands of loci at the same time.
Instead a much more realistic pathway to reducing mutational load would be embryo selection. Currently in the case of IV fertilization up to ten embryos are created, because not all of them will be viable and the process of ovum extraction is not something you’d want to repeat. One of these embryos is implanted into the uterus and the only selection that is going on in the moment is for genetic diseases, mostly chromosome aberrations. Of course if you already have ten embryos anyway, you might as well select the one which is most likely to grow into a happy, healthy and intelligent human being.
The easiest way to do this is single cell sequencing from placental cells (this reduces the likelihood of damage to the embryo). Single cell sequencing doesn’t contain enough information to pinpoint the number of negative mutations directly, but it is more than enough to determine which parts of the parental chromosomes are present. The parental genomes can be sequenced with more depth and the mutational load determined with very high precision for each stretch of each chromosome, which ultimately allows us to sort embryos by mutational load.
For ten embryos, of which a number is not going to be viable anyway, this selection would lead to results that are statistically very relevant, but not necessarily noticeable on an individual basis. Given that embryo selection already happens on the basis of other medical diagnosis and morphological appearance and given that the selection is not explicitly based on IQ or other specific traits, it also wouldn’t be a paradigm shift towards eugenics and might meet relatively little public opposition.
What is the smartest kid you could have, compared to your and your spouses mean IQ of X? That is, if you could pick one out of each of your chromosome pairs such that the genetic endowment for intelligence of the resulting collection is maximized and your partner does the same, how high would we expect the IQ of the resulting kid to be?
Now, this isn’t even going to be the maximal possible IQ for your offspring, because we ignore recombination, which in principle allows the selection of sections of chromosomes instead of full chromosomes. It’s just a lower bound, what I call an insanity check, for what emryo selection, chromosome selection, DNA synthesis or Crispr/CAS9 might one day make possible.
First we have to take regression to the mean into account. Regression to the mean happens, because outliers are created by extraordinary genes and luck. Luck in this case may be special environmental factors (like unusually few early childhood infections) or non-linear interactions between your chromosomes (like certain negative mutations occurring unusually often only on one chromosome, allowing the other one to jump in). Afaik in IQ it amounts to 20% of the deviation from the population mean. So if your and your spouses mean IQ is , we’ll discount (or raise) that number to . That is the expected mean IQ of your children.
One way to look at our question is: If you had an infinite number of children, where would you max out? We need two pieces of information for our calculation: How many is “infinite” and what is the standard deviation in siblings. It turns out that if you ignore recombination, which is what we do, “infinite” amounts to , after that we run out of chromosome combinations and we’ll start to repeat ourselves with genetically identical kids. We expect the standard deviation in siblings to be . How much of an outlier is one in ? Well, the Z-score for is 7.605, which multiplied with the siblings std.dev. of 10.6 equals 80.613 IQ points out from the siblings mean. No matter what kind of parents you start out with, that’s one smart kid.
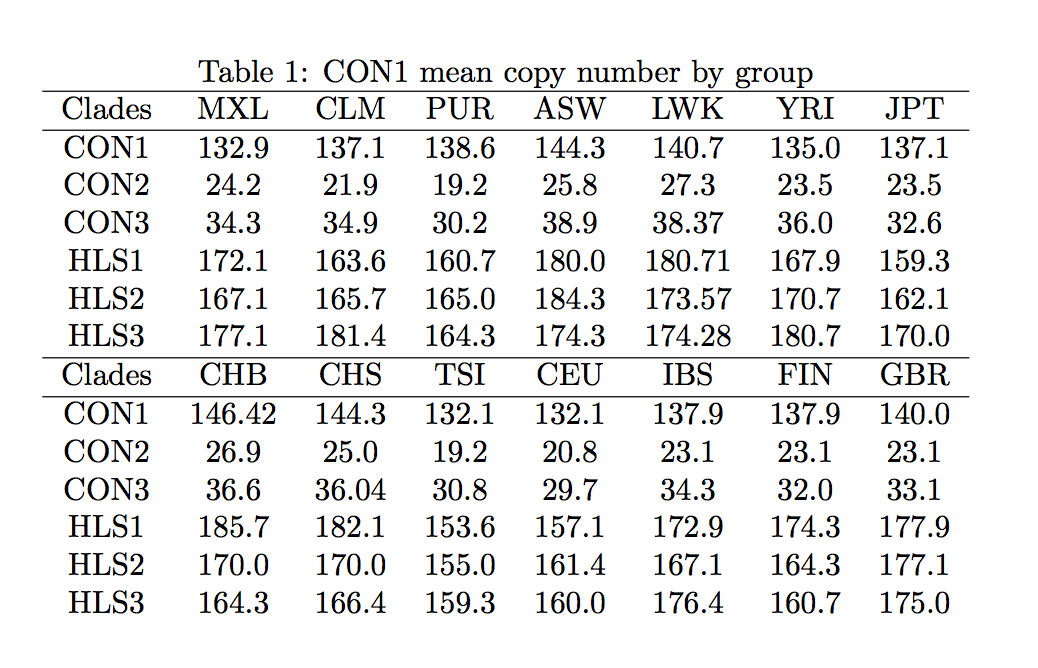
Duf 1220 is a fascinating specimen [1]. It’s a protein domain, i.e. a conserved part of a protein, and mammals generally have several copies of its coding sequence. The number of Duf 1220 copies rises with increasing cognitive sophistication of the animal. It correlates with brain size and number of neurons in the neocortex. Humans underwent rapid copy number expansion since our split from Chimpanzees, so it might just be an essential part of what made us human.
There are several slightly different versions of Duf 1220: Three versions conserved in mammals, CON1, CON2, CON3, and three human lineage specific versions, HLS1, HLS2, HLS3. CON1 copy number variation has been correlated with symptom severity in both autism and schizophrenia. More copies increase the severity of autism symptoms [2], but ameliorate the symptoms of schizophrenia [3]. This is a data point in favor of a hunch many people seem to have, that autism and schizophrenia are to a certain degree opposites.
The more interesting finding, however, concerns CON2. There is a 2014 paper that shows a correlation between CON2 copy number and IQ, as well as between CON2 copy number and mathematical aptitude in two different populations [4]. And while the correlation is not very strong, the effect size is pretty big: A one copy increase is associated with a rise of 3.3. IQ points (CON2 copy numbers varied from 26 to 33).
There is a caveat here, that the populations had been selected for unusual brain sizes, apparently because Duf 1220 mutations have also been implicated in cases of microcephaly and macrocephaly. So it is hard to say how this would generalize to the population at large. There also hasn’t been a try yet to replicate this result, though the whole genome sequencing data that UK biobank is aggregating in 2018/19 should be ideal for that, so hopefully it is only a matter of time.
This could present a major roadblock for polygenic scores for IQ that capture a significant part of the variation. These polygenic scores are computed on the basis of SNP-sequencing, so basically a couple of hundred thousand known genetic variants are looked up for hundreds of thousands of people and then these variants are correlated with a measure of IQ. Such polygenic scores are expected to capture almost all of the genetic variation in one of the upcoming studies, as the data sets approach a million genomes and more. SNP-data, however, doesn’t give you copy numbers. So if a significant part of the genetic variation in IQ is due to copy number variation, the upcoming polygenic scores for IQ will miss out on that.
There is another major thing Duf 1220 exploration might bring about. For better or for worse, it might give an undeniable genetic underpinning to IQ differences between ethnic groups. This is something polygenic scores cannot do fully convincingly. Because they were calculated on the basis of a particular population, there is always the possibility that other populations just have other causal variants, or maybe the same causal variants but tagged by different non-causal variants. Duf 1220 copy numbers provide an absolute scale. If they are strongly correlated with IQ and some groups just have more copies, that would be it.
There is data out there to test this hypothesis. The 1000 Genomes Project has collected whole genome sequencing data from more than 2000 persons coming from a few dozen different populations [5]. I was already gearing up to find out how to extract the copy numbers directly from the genome data. It would have been pretty annoying, starting with the fact that Duf 1220 has changed names three times and is not even a full protein, so it was already difficult to find out the exact sequences I was going to look for [6].
Thankfully, I came across a paper that presented a new method to accurately extract the Duf 1220 copy numbers from crappy whole genome data … such as provided by the 1000 Genome Project [7]. So I could just extract the copy numbers for each population from this paper and calculate the correlation with national IQ. They calculate the copy numbers for only a subset of the genomes (300 out of >2000) and ethnicities (14 out of 26), so it would still be interesting to do this for the whole data set, but for me this is obviously good enough.
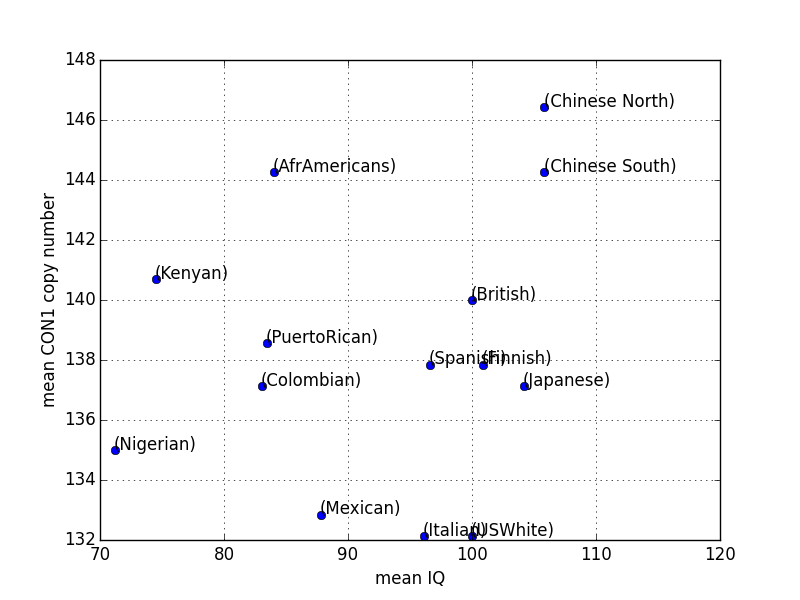
I extracted the mean copy numbers with a ruler from a figure, but it should be reasonably accurate. The population code is MXL, CLM, PUR, ASW, LWK, YRI, JPT, CHB, CHS, TSI, CEU, IBS, FIN, GBR for Mexican, Colombian, Puerto Rican, African American, Kenyan, Nigerian, Japanese, Chinese North, Chinese South, Italian, US White, Spanish, Finnish and British. I must say, the big differences between US whites (CEU) and the British (GBR) sample make me suspect that these samples are not terribly representative.
Here are the correlations and p-values of the copy numbers of these different Duf 1220 clades with mean IQs (mostly taken from [8])
So the only correlation <0.05 is actually negative! And given that we tested five hypothesis in parallel here, not even that one can be called statistically significant.
However, if we take a look for example at the figure for CON1, there is a visible correlation on the right hand side, which corresponds to Eurasians. And indeed, if we restrict the data only to the Eurasian groups, we get two strong positive correlations with p<0.05 for CON1 and CON2. Of course, this proves nothing at all, except that eyeballing data is enough to conjure low p-values out of thin air.
[3] DUF1220 copy number is associated with schizophrenia risk and severity: implications for understanding autism and schizophrenia as related diseases https://www.nature.com/articles/tp2015192
[4] DUF1220 copy number is linearly associated with increased cognitive function as measured by total IQ and mathematical aptitude scores. https://www.ncbi.nlm.nih.gov/pubmed/25287832
Currently available nootropics don’t seem to increase IQ. In fact basically nothing increases IQ, despite many claims to the contrary. Instead nootropics like modafinil, adderal, coffein, nicotine, etc. improve focus or endurance or energy level. Consequently, the difference in productivity is quantitative not qualitative.
If we could increase IQ by, say, ten points, simply by popping a pill, it would make a tremendous difference not just on an individual level, but especially on a societal or global level.
To see what difference ten points would make, take a look at the Ashkenazim. Ashkenazim are the Eastern and Middle European Jews and they are massively over represented in all cognitively demanding fields. Their total number was probably never higher than 15 million. However, roughly half of all chess world champions have had Ashkenazi ancestry, as well as more than 20% of all nobel prize winners [1]. In some fields, like economics, more than 40% of all nobel prize winners are of Jewish ancestry.
To illustrate how unusual that is, please try to name 3 famous Belgian thinkers or scientists. Unless you are from Belgium yourself, you’ll probably come up empty handed. If you make the same experiment for Ashkenazim your only problem might be that you possibly don’t know that Einstein, Marx, Freud, Von Neumann, Feynmann, Kasparov, Bobby Fischer and many others were Jewish. The theory of relativity, the nuclear bomb and modern computer architectures are all result of Ashkenazi genius.
This massive intellectual over performance is to a large part the result of an IQ advantage of just ten points [2].
On a societal level an advantage of ten points corresponds to a doubling of the GDP per capita. For comparison: Globally it took 45 years for GDP per capita to double between 1969 and 2014 [3]. Gaining this additional boost would make a massive difference, likely enough to eliminate all remaining poverty.
We also seem to live in a time where several massive problems are on the horizon, and we can certainly use all the smarts we can get to have a chance to solve them.
To sum up: A cheap and side-effect free pill that enhances IQ by ten points would usher in a technological and scientific golden age, accompanied by massive economic growth.
So how did the Ashkenazim level up? Cochran and Harpending make a convincing case that Ashkenazim IQ rose during the last thousand years to its current heights, due to strong selection for white collar work acumen [4]. Remember, during the middle ages crafts and farming was largely forbidden for Jews, leaving different kinds of businesses as possible occupation. Financial success was strongly correlated with surviving number of children.
One strong indicator for this selection is a cluster of genetic diseases unusually common in Ashkenazim. These are, for example, the so-called sphingolipid storage diseases like Tay-Sachs or Gaucher’s disease. These diseases are caused by loss-of-function mutations in enzymes that break down sphingolipids in cells. If such an enzyme doesn’t do its job, sphingolipids accumulate and over time lead to different neurological disorders.
Also, genetic diseases connected to DNA-repair dysfunction and miscellaneous stuff like Torsion dystonia. The kicker is that all these diseases likely rose to their current high frequency as by-product of strong selection for intelligence. In Israel people with Gaucher’s disease are six times as likely to be engineers or scientists as other Ashkenazim. Torsion distonia sufferers have been shown to have an IQ elevated ten points above the already high Ashkenazi mean [5].
There is also in vitro evidence for increased dendritic growth under high sphingolipid concentration. So while a homozygous carrier of Tay-Sachs is doomed to an early death, a heterozygous carrier profits from higher sphingolipids concentrations in his neurons and consequently higher dendritic growth, while the one working gene copy is still enough to clear out enough sphingolipids to avoid detrimental symptoms.
A very similar argument of strong selection for IQ, albeit over a significantly shorter time span, was made for French Canadians by Peter Frost, on the basis of an overlapping but not identical cluster of genetic diseases [6]. Here we get a list including several genetically mediated vitamin D deficiencies. Apparently vitamin D limits neuronal growth, and if intelligence is evolutionary very high-return, rickets takes a backseat.
Additionally, there is this Scottish family, where all members with a certain mutation, sport a 20 point verbal IQ advantage over those members without the mutation [7]. Unfortunately, they also go blind in their early twenties.
So, these cases gives us a rather long list of proteins, whose inhibition is likely to increase IQ. To me this sounds like a perfect opportunity to design drugs to target these proteins. The potential IQ gains are very considerable.
Of course if you inhibit these proteins completely you will get a nasty disease. But these diseases are very slow acting, so you probably have plenty of time to go off the stuff once you develop symptoms. Also, given this long list, you could cycle through different drugs/proteins evading negative symptoms while keeping the IQ benefit.
There is the possibility that the effect is limited to embryo genesis or early childhood development.This would make drug testing highly problematic. But given that newborn’s brains are already stuffed with synapses anyway, this seems quite unlikely for the dendritic growth enhancing diseases. So this problem is likely limited to the vitamin D diseases and those might be less promising anyway.
But even if the probability of this research avenue resulting in a side-effect free drug, that enhances IQ by some ten points or so, is only 0.1%, and even if it costs a billion dollars to design and test these potential drugs, the expected return is still pretty overwhelming.
So let’s say monday SpaceX, tuesday Tesla, wednesday Boring Company, thursday Neuralink, friday Open AI, and instead of smoking pot with Joe Rogan on saturday, how about a drug designing startup on saturday, that might just save the world?

 , we’ll discount (or raise) that number to
, we’ll discount (or raise) that number to  . That is the expected mean IQ of your children.
. That is the expected mean IQ of your children. , after that we run out of chromosome combinations and we’ll start to repeat ourselves with genetically identical kids. We expect the standard deviation in siblings to be
, after that we run out of chromosome combinations and we’ll start to repeat ourselves with genetically identical kids. We expect the standard deviation in siblings to be  . How much of an outlier is one in
. How much of an outlier is one in  is 7.605, which multiplied with the siblings std.dev. of 10.6 equals 80.613 IQ points out from the siblings mean. No matter what kind of parents you start out with, that’s one smart kid.
is 7.605, which multiplied with the siblings std.dev. of 10.6 equals 80.613 IQ points out from the siblings mean. No matter what kind of parents you start out with, that’s one smart kid.